Git
Imagina que eres un escritor (indistintamente del contexto o lenguaje) y encuentras útil llevar una bitácora de cambios de tus artículos o textos (sobretodo si son digitales) por lo que requieres de una herramienta que te posibilite hacer eso. Del mismo modo, al desarrollar en equipo se requiere de una herramienta de control de versiones, es decir, aquella que gestione los cambios para producir una versión unificada en un momento dado, eso hace Git. Por otra parte, independientemente de si se trata de un equipo de trabajo o de un único desarrollador, existe el riesgo de perder versiones entre los cambios del software o la necesidad de regresar a un cambio anterior, por lo que se hace necesario un sistema de control de versiones para llevar el historial de cambios del software.
Y no solamente se trata de software, podría utilizarse como apoyo en un sistema de gestión de documentos de los cuales se desea controlar versión, tal es el caso de una organización o de un escritor de artículos. Sin embargo, se saca un verdadero provecho si los archivos son de texto plano (no binarios). Por ejemplo, usar un archivo de texto en convención Markdown (.md) en lugar de un archivo escrito en un procesdor de palabras que produce un binario o empaquetado, puesto que con archivos de texto (plano) es posible identificar las diferencias entre versiones.
Evítese confundir
Git(creado por el fundador de Linux) conGitHub(actualmente de Microsoft), esta última usaGitpara proyectos con repositorios remotos, es decir, presta un servicio relacionado con proyectos que usan Git como su sistema de control de versiones (VCS) para gestionarlos en la nube y agregar algunas caracteristicas.
Si comprender Git llegara a tomar más de 2 horas, es insignificante si se considera que es indispensable en el desarrollo de software, dado que un proyecto de software formal debería tener algún control de versiones y actualmente Git es la herramienta más popular para esa tarea.
Conceptos esenciales
-
Sistema de Control de Versiones. Conocida en inglés por las siglas VCS, es la herramienta que gestiona los cambios de las versiones de un proyecto de desarrollo de software a nivel de archivos del producto software. En este caso hablaríamos de
Git. -
Repositorio. Carpeta que se asocia a un VCS (como
Git) para hacer seguimiento llevando un historial de cambios. Puede ser local o remoto. La idea de usar un repositorio remoto toma cada vez más fuerza en equipos de trabajo distribuidos en diversas ubicaciones, es lo que posibilitan servicios comoGitHubentre otros, aunque también podría públicarse una máquina en internet para ese fin. -
Ramas (Branch). Podrían verse como derivaciones internas del mismo proyecto que varían dado un seguimiento en particular, por ejemplo, se cuenta con la rama master, que debe ser administrada por un lider, y la rama dev para el equipo de desarrollo en general. En realidad consiste en apuntadores a las confirmaciones (commit), de modo que no es una copia en sí, sino una bitacora separada.
-
Commit. Evento en que se indica que un cambio tuvo lugar y se entrega.
-
Clone. Evento en el que un desarrollador hace una copia del repositorio en su equipo localmente. Es la manera de trabajar con este VCS, en dónde cada desarrollador tendría una copia del repositorio para continuar con sus propias actividades de desarrollo, de modo que requerirá en algún momento integrase sus cambios con commit
-
Fork. En lugar del concepto de rama, se trata de un nuevo proyecto, tendría un historial aislado que seguirá su propio camino basándose en un repositorio anterior.
-
Merge. Evento en que se fusionan los cambios de los diferentes desarrolladores de proyecto para crear una versión. Pueden presentarse inconvenientes en dónde deben resolverse el orden de los cambios, generalmente lo hace un líder verificándo los detalles con su equipo.
-
Directorio de trabajo (Working Directory). Se refiere a la carpeta que se utiliza localmente por un desarrollador en su máquina, por ejemplo, cuando se clona un repositorio. Hace parte de la estructura de Git junto con index (relacionado con
staging area) y HEAD. -
Index. Como parte de la estructura de Git se gestiona una lista de registros indexados relacionados con cambios reportados, lo cual sirve internamente para identificar lo que se encuentra pendiente de confirmar (en la
staging area). -
HEAD. Es otra parte de la estructura que contiene encabezados de los cambios confirmados.
Comprendiendo el flujo de trabajo esencial
📂 Working Directory
~>Index (stage)~>Local repo (HEAD)~>Remote repo (MASTER)
Generalmente, cuando un desarrollador se incorpora a un proyecto ya existente (creado con anticipación usando git init) lo que requiere es clonar el repositorio (usando en su lugar git clone). En cualquier caso lo que se busca es contar con un directorio de trabajo basado en el repositorio base.
Partiendo de un directorio de trabajo (working directory), que es una carpeta que opera como el espacio de trabajo donde se encuentra el proyecto con los fuentes, se usa luego una zona intermedia (index, relacionado con staging area) para gestionar los cambios pendientes. Finalmente se tiene una estructura para los cambios confirmados denominada HEAD.
Cuando se hace un cambio se debe reportar con el comando git add. Al hacer esto se tiene una serie de cambios pendientes por confirmar (index). Cuando se confirman los cambios con el comando git commit se establecen en HEAD (que contiene los últimos cambios confirmados de los archivos respectivos) que corresponde al respositorio local (local repo).
Al contar con un repositorio remoto (remote repo), que usualmente se define como MASTER, después de hacer la confirmación y revisión de todos los cambios requeridos se integran en el repositorio remoto con el comando git push.
git clone~>git add~>git commit~>git push
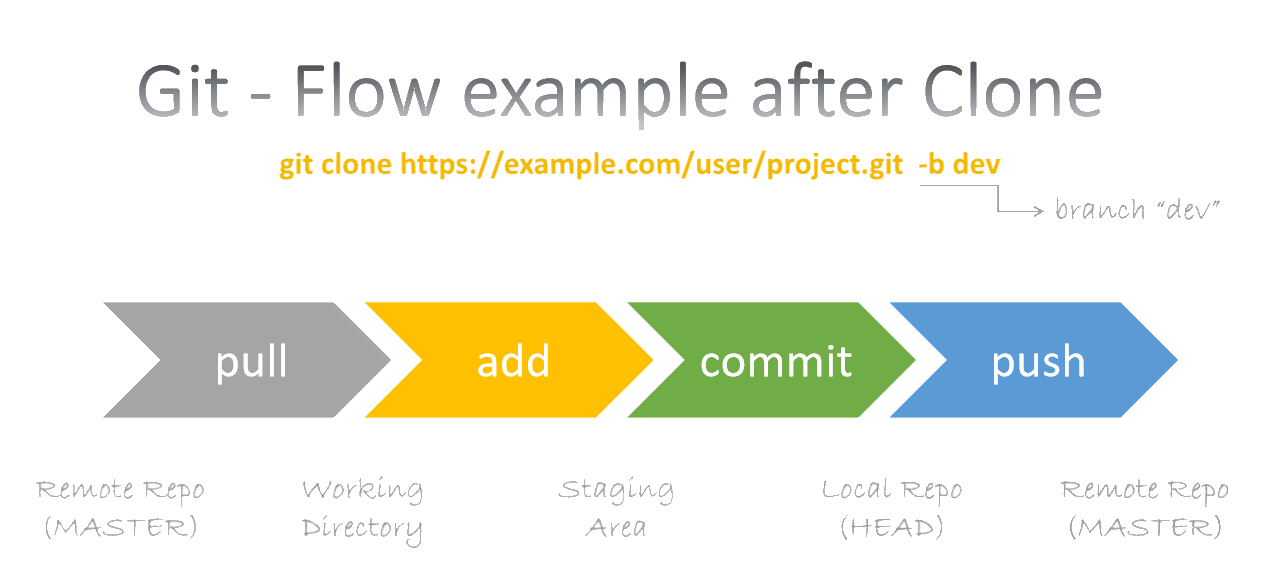
Cuando un proyecto se ha clonado o inicializado suele aplicarse el flujo ilustrado.
git pullse usa en lugar de clonar para tomar cambios de otros (sincroniza nuestro directorio de trabajo), por lo que es aconsejable usarlo antes de confirmar nuestros cambios.
Pasos iniciales
Para iniciar un proyecto apoyado en un VCS como Git, debe crearse la carpeta o usar la de un proyecto existente. Para comprender bien Git es aconsejable usar la línea de comandos, de modo que debes ubicarte dentro de ella para crearla como un proyecto de Git y configurar tu nombre y usuario de ahora en adelante (si no se ha hecho antes en la máquina). Veamos:
cd project
git init
git config --global user.name "username"
git config --global user.email "[email protected]"
Como es más común que un desarrollador tome los archivos de un repositorio ya existente, en ese caso se usaría (en lugar de git init) el comando git clone seguido por la ruta local o URL remota que se le indique. El comando git config --global normalmente se ejecuta una sola vez por cuenta de usuario en un equipo.
Se debería agregar un archivo
.gitignorecon la lista de archivos, directorios y carpetas que se ignoran al no requerir control de cambios. Avanzando este texto se encontrarán un par de ejemplos de este archivo. Podría anticiparse que si se trata de un proyecto enNode.jsse puede iniciar usando:
echo node_modules > .gitignore
Para reportar un cambio se usa git add seguido por el nombre del archivo (o git add . si es toda una carpeta), mientras que para confirmarlo se usa git commit con un comentario. Por ejemplo:
git add .
git status
git commit -m "Initial version"
git log
Cuando ejecutas
git addse indica que archivo se prepara o usa, o tiene cambios pendientes por confirmar en una zona denominadastaging area(la cual sirve internamente para identificar lo que se va a confirmar congit commit). Puedes consultar el historial de cambios confirmados congit log.
Cuando se comprenda la dinámica puedes usar un editor o un IDE que facilite marcar los cambios de modo ágil y confirmarlos (comprendiendo que internamente se estaría usando git add o git commit según corresponda). Por ejemplo, VSCode (Visual Studio Code) tiene en la barra lateral de iconos un gestor de cambios que identifica y lista archivos modificados recientemente, de este modo, proporciona operaciones sobre el archivo para descartar cambios o agregar a la lista de pendientes por confirmar, así como en la parte superior de esa sección se encuentra la opción de confirmar. Adicionalmente, existen herramientas enfocadas en gestionar el repositorio (como GitKraken) que posibilitan la tarea de resolver conflictos y tener una disposición visual del historial de cambios, siendo también de gran ayuda para integrar los cambios del equipo en MASTER (función que generalmente ejerce un líder).
Si te incorporas recientemente a un proyecto dónde el repositorio ya existe, lo primero que haces es clonarlo. Para esto requieres la url del repositorio, por ejemplo:
git clone https://github.com/user/project.git
Puedes agregar
-b deval final si deseas establecer inmediatamente una rama de desarrollo (deves comunmente usado pero puede tener otro nombre).
El archivo “.gitignore”
Se puede crear un archivo .gitignore en la raíz del repositorio para indicar los archivos que no intervienen en el proceso por no corresponder al repositorio. Generalmente, en un repositorio solo se gestinan fuentes que suelen ser archivos de texto (planos), salvo tecnologías donde el fuente sea binario o el caso de imágenes e iconos de proyecto, lo demás se debería ignorar.
Un ejemplo de .gitignore en un proyecto bajo Node.js, podría lucir de la siguiente manera:
node_modules/
build/
dist/
cache/
typings/
run/
file-uploads/
npm-debug.log*
yarn-debug.log*
yarn-error.log*
firebase-debug.log*
*.log
*.tgz
*.pid*
pids
.npm
.env
.serverless
.firebase
.haxerc
.DS_Store
Thumbs.db
Un ejemplo de .gitignore en un proyecto bajo JVM, podría lucir de la siguiente manera:
*.class
*.jar
*.war
*.log
file-uploads/
lib/
bin/
target/
build/
gradle*
.gradle
.nb-gradle
.idea
.settings
.classpath
.project
.vertx
.DS_Store
Thumbs.db
hs_err_pid*
Resumen de comandos frecuentes
| Comando | Descripción |
|---|---|
git init |
Aunque no es frecuente, es el comando esencial para inicializar un repositorio con Git. Agrega la carpeta .git. |
git clone |
Alternativamente al anterior comando, es el usado cuando ya existe un proyecto definido para clonarlo. Si es local requiere la ruta del repositorio. Si es remoto aplica el formato username@host:/path/to/repo |
git config |
Permite establecer cierta configuración por defecto para los commits, como el usuario y el email. |
git add |
Agrega el archivo para indicar que está siendo alterado o será alterado (preparándo el desarrollo), dejándolo en la staging area. |
git status |
Consulta los archivos agregados a la staging area para ser confirmados. |
git commit |
Pasa los archivos cambiados (de la staging area) al repositorio local quedando confirmados con un mensaje. Se puede usar -m para indicar el mensaje u omitir parámetros, en cuyo caso el mismo comando solicita el mensaje. |
git log |
Visualiza el historial de cambios hechos por el desarrollador que usa el directorio de trabajo local. |
git reset |
Desconfirma cambios, siendo útil cuando debe reestablecerse algo. |
git checkout |
Se puede usar para crear ramas (-b) o cambiarse entre ellas, por ejemplo git checkout master |
git push |
Pasa los archivos confirmados del repositorio local a el repositorio remoto, por ejemplo en GitHub. |
git fetch |
Obtiene una copia de los archivos del repositorio remoto a el repositorio local, es decir que actualiza e intenta sincronizar otros cambios recientes que han llegado al repositorio remoto. |
git merge |
Integra los archivos del directorio de trabajo en el repositorio. |
git pull |
Suma las funciones de fetch y merge. Puede usarse antes de commit para obtener primero cambios recientes en el repositorio remoto. |
git tag |
Permite establecer etiquetas en nuestro proyecto siendo útil para versiones (releases) |
git diff |
Compara cambios realizados sobre archivos planos del repositorio. |
Material Complementario
Para apoyar el conocimiento y reforzar el aprendizaje desde otra óptica, se recomiendan los siguientes recursos:
- https://rogerdudler.github.io/git-guide/index.es.html
- https://rogerdudler.github.io/git-guide/files/git_cheat_sheet.pdf
- https://www.atlassian.com/es/git/tutorials/setting-up-a-repository
- https://www.youtube.com/watch?v=3a2x1iJFJWc (video)
Proyecto de ejemplo
Vamos a crear una carpeta para el proyecto (por ejemplo project) y abrimos un editor de texto que accede al contenido de la carpeta (como VSCode o Sublime). En la carpeta tendremos un archivo readme.md, es decir, encontraríamos lo siguiente:
- 📂 project
└─ readme.md
Veamos el contenido de nuestro archivo readme.md:
# Tips sobre Git
1. `git init` lo usas cuando creas un proyecto para `Git` desde cero dentro de una carpeta existente
2. `git add .` marca los archivos dentro de la carpeta para agregarlos al repositorio
3. `git commit -m "..."` confirma los cambios reportando un mensaje o comentario
Ejecutamos desde la terminal (o consola) los comandos:
git init
git add .
En la carpeta del proyecto se ha generado un subdirectorio .git que corresponde al repositorio pero se encuentra oculto, es decir, si se hace visible el subdirectorio .git la carpeta se vería asi:
- 📂 project
├─ .git
└─ readme.md
Ahora confirmamos los cambios con el comando:
git commit -m "Start"
Encontraremos que se genera una rama principal con nombre master. Para crear ramas propias y no tocar a master se usa el comando git checkout -b con el nombre de la rama. Veamos:
git checkout -b branch-x
Modifiquemos el archivo readme.md de modo que quede con el siguiente contenido:
# Tips sobre Git
1. `git init` lo usas cuando creas un proyecto para `Git` desde cero dentro de una carpeta existente
2. `git add .` marca los archivos dentro de la carpeta para agregarlos al repositorio
3. `git commit -m "..."` confirma los cambios reportando un mensaje o comentario
4. `git checkout -b ...` crea una rama indicando el nombre para no tocar a `master`
5. `git push` se usa después de `commit` cuando trabajas con un repositorio remoto para enviar los cambios
6. `git clone` es el primer comando que usas para descargar un repositorio de un proyecto existente
7. `git pull` puede usarse antes de `commit` para sincronizar cambios de otros
Agregamos los cambios y los confirmamos, esta vez quedarán en la nueva rama. Recordemos los comandos:
git add .
git commit -m "Plus..."
Cuando ya existe un repositorio es importante tener presente lo siguiente:
git clone ...lo primero que usas para clonar y/o descargar un repositoriogit checkout ...para trabajar en una rama (como se ha visto antes)git pull ...puede usarse antes decommitpara sincronizar cambios de otrosgit commit ...para confirmar los cambios (después de agregar congit add)git push ...para enviar los cambios al repositorio (luego degit commit)
Adicionalmente, podemos agregar etiquetas para identificar versiones, por ejemplo:
git tag version-alpha -m "Version Alpha"
git push --tags
Y si tienes algún problema en el que requieres devolver un cambio, teniendo cuidado si es la rama principal o master, incluso poniendo al tanto al equipo, puedes ejecutar lo siguiente:
git reset HEAD~1
git push origin +HEAD
En la primera línea se devuelve un cambio local, también podría usarse
git reset HEAD^. En la última línea se devuelve el cambio remoto (solo se usa si se ha aplicado)
En ocasiones, cuando aplicas la estrategia GitFlow es necesario recoger un commit especifico para aplicarlo a una rama base. Para esto se usa el comando cherry-pick y luego puedes subir los cambios (push) a esa rama base. Veamos el ejemplo:
git cherry-pick abc123 -m 1
git push origin main
El comando
cherry-pickrequiere que se le reporte elcommit. El parametro-m 1se usa principalmente con Pull Requests. Finalmente se ejecutapush
© 2019 by César Arcila