OnMind-XDB - eXpress Database (antes DCE)
.:[ See in English ]:.
Descargar…
Este es un documento que presenta OnMind-XDB (la edición de base de datos eXpresa de OnMind) para acompañar proyectos y como base de conocimiento o referencia técnica y uso pricipalmente local. OnMind-XDB no tiene costo por licenciamiento, tampoco garantía alguna, pero es posible pasar a un esquema empresarial con la plataforma OnMind y sus productos. Se ha escrito usando lenguage Kotlin.
También se está diseñando otra versión de base de datos gratuita, que se piensa denominar OnMind-WDB (Wide/Web Database), para fines de la nube. Se considera usar KotlinJS.
Casos de uso de OnMind-XDB
OnMind-XDB puede ser de gran utilidad en proyectos personales o académicos, y para aplicaciones dirgidas a pequeños negocios. Sin embargo, su potencial puede ser utilizado en proyectos de integraciones (ver video al final interactuando con MuleSoft), incluso blogs (como headless-cms) o como una gran hoja de datos.
Otra faceta clave consiste en orientarse a Mockup, para prototipado ágil de la interfaz de usuario. Así como también, para apoyar funcionalidades de marketing digital y proyectos ágiles.
Quizás también podría llegarse a cosiderar una versión específica para Móviles o IoT (Internet of Things). De hecho, se ha estado diseñando la versión OnMind-WDB para la Nube.
La primera cosa que debes hacer para utilizar este programa es descargar el software portable, leer el archivo README.md y ejecutar el archivo onmind-xdb... respectivo. Luego podrás crear tu primer objeto. por ejemplo, copiando en el programa lo siguiente:
{
"what": "create",
"some": "example"
}
CTRL + Rse usa para ejecutar la sentencia
Ejemplo de uso esencial
Si tienes conocimientos técnicos avanzados haremos un ligero paréntesis antes de la introducción conceptual, que por supuesto invitamos a revisar para comprender el contexto. OnMind-XDB es una base de datos NoSQL que para consultar y gestionar la información implementa una API (Application Programming Interface) con JSON (Javascript Object Notation) que se ha denominado “Articulable Backend Controler”, o “Articulable Backend Client” cuando se trata de una aplicación (cliente), y es una propuesta del autor de OnMind como especificación o estándar tecnológico que se alcanza a ilustrar con el ejemplo a continuación:
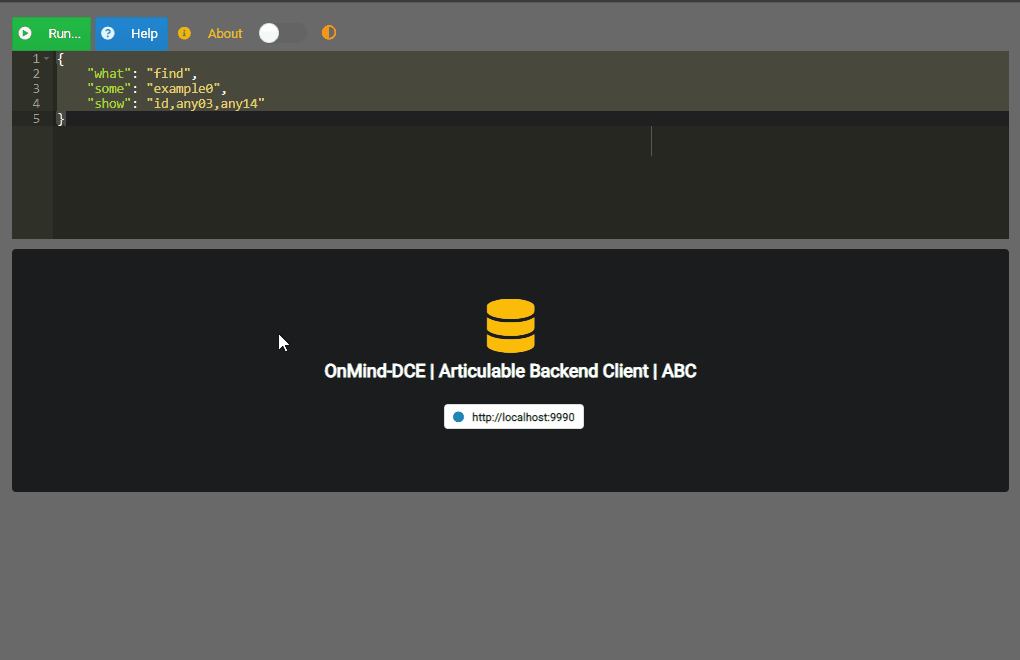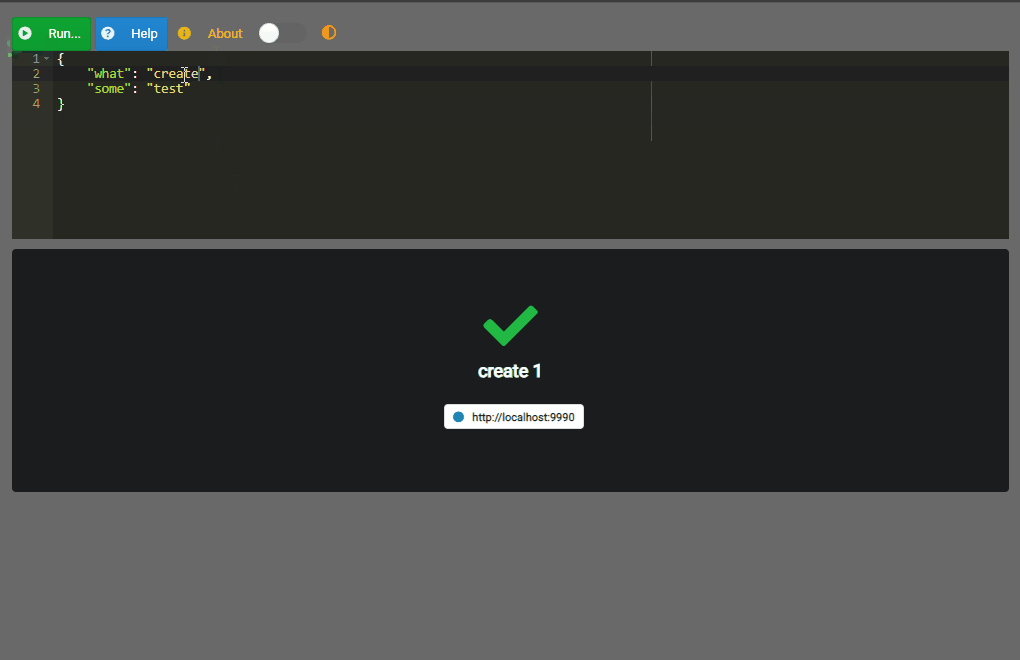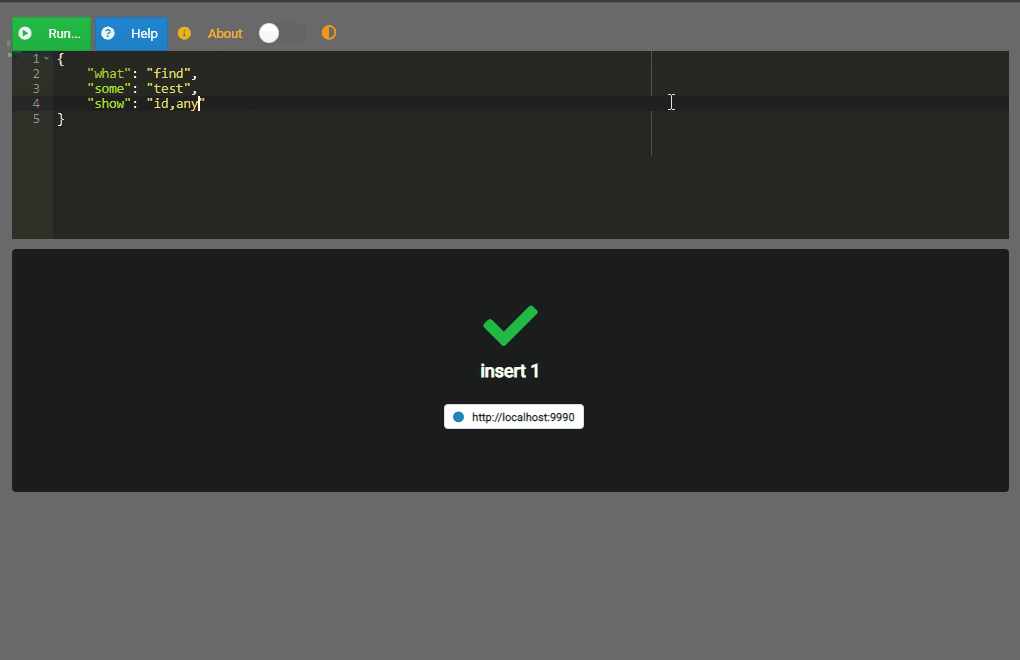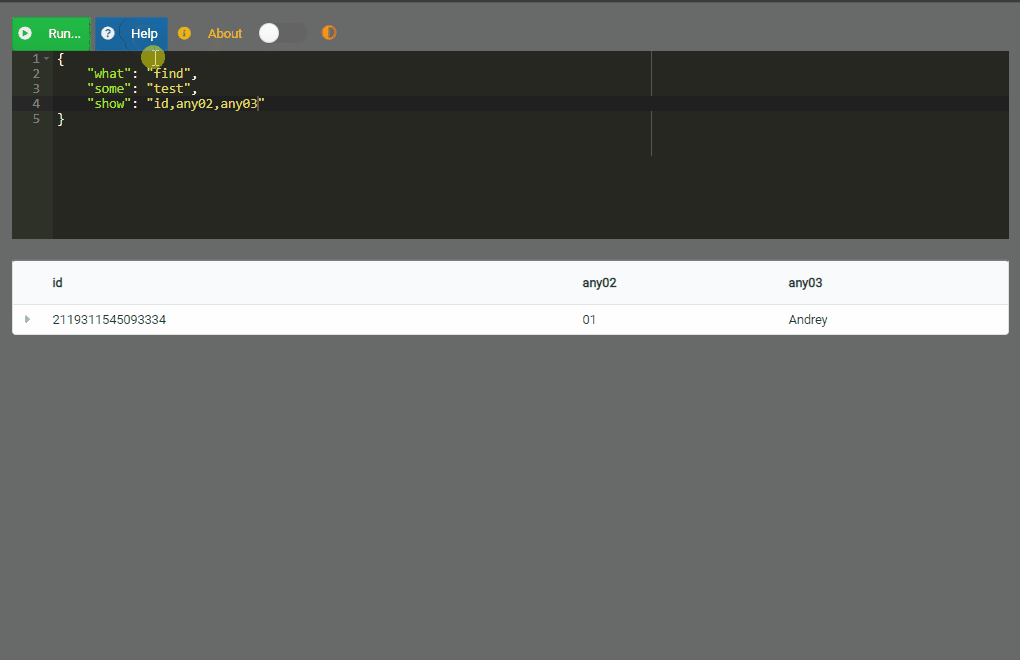
{
"what": "find",
"some": "example",
"show": "id,any02,any03"
}
Se puede observar que se indica
what,someyshowqueriendo representar respectivamente “qué acción”, “sobre qué cosa” y “qué mostrar”. En este ejemplo esencial la acción esfind(encontrar), la cosa esexampley luego se enumeran los datos a mostrar separando con comas (,).
Por supuesto que se puede aplicar un criterio o condición para filtrar información (para lo cual se usaría el elemento with) pero esto se podrá encontrar avanzando en esta documentación. Dado que los datos se muestran sólo si se encuentran o existen, veamos un ejemplo esencial sobre como agregar la información, considerando que se usarán ciertos atributos predefinidos: any02 (id), any03, etc.
{
"what": "insert",
"some": "example",
"puts": {"any02":"01","any03":"Andrey"}
}
Aquí podemos decir que la acción es
insert, la cosa esexamplepero luego aparece el elementoputsen donde se reportan los datos enJSON(si se va a consumir el servicio se envían datos separados por punto y coma;como se verá posteriormente).
Por supuesto que antes de insertar información se debe haber definido la cosa (some), veamos cómo…
{
"what": "create",
"some": "example"
}
El
endpointprincipal suele ser:localhost:9990/abc. Lo más apropiado es seguir los pasos en orden inverso.
En este ejemplo esencial se han expuesto ciertos principios que ilustran una idea. Por ahora se invita a revisar los conceptos y contexto de esta propuesta tecnológica.
Sobre el Autor
César Andrés Arcila…
¿Qué es una Base de Datos?
Es un mecanismo y programa de computador en donde se almacenan datos debidamente organizados, en inglés “database”. Generalmente, las aplicaciones para negocios hacen uso de un programa gestor (o motor) de base de datos que pertenece a un fabricante distinto y que puede generar un costo adicional, si bien existen alternativas decentes de bases de datos sin generar costos por licenciamientos (distinto cuando se trata del soporte). En muchos casos, para acceder a la información estos motores de datos usan un lenguaje estructurado de consulta (conocido como SQL), como alternativa, aquellos gestores que no lo usan entran en un grupo denominado NoSQL.
¿Para qué sirve una Base de Datos?
Las bases de datos posibilitan el acceso rápido y organizado a los datos y alimentan aplicaciones informáticas que suelen ser del campo de negocios o analítica, así como diversos campos. Mientras se pueden aplicar algunos principos de base de datos mediante hojas de cálculo de modo artesanal, ello no sería equiparable a un motor de base datos como tal. De hecho, este tipo de tecnología se conoce también como sistema de gestión de base de datos (siglas DBMS en inglés) y es aplicable a negocios de cualquier tamaño, siendo la base para obtener información del negocio, lo cual es clave.
¿Qué es OnMind-XDB?
Es el gestor de base de datos de edición comunitaria de OnMind que es posible instalar localmente. OnMind-XDB se basa en una versión interna de la plataforma, liberándose de un modo desacoplado (externa o independiente de la plataforma OnMind) y sin la interfaz gráfica de usuario. Se clasifica como NoSQL dado que en lugar de SQL implementa una API (Application Programming Interface). OnMind-XDB tiene un enfoque local y no incluye mecanismo para hacer respaldos, entendiéndose que es fácil encontrar herramientas adicionales para respaldar archivos locales y cubrir tal actividad (por ejemplo: Cobian Backup o FreeFileSync).
OnMind-XDB no es un producto ideal para la nube ni para manejar un archivo que supere 1GB, para ello encuentras otro producto de OnMind. La propuesta de este gestor de base de datos implica que los arhivos de medios, tales como imágenes, videos o documentos, se gestionan mediante otros mecanismos como una simple carpeta (o un servicio en la nube como Dropbox). Es decir, el producto está diseñado para datos planos o referencias a archivos externos (enlaces) y no para almacenar tales archivos. Por ello, el almacenamiento de datos puede ser de 10MB al comenzar y para llegar a 1GB (mil veces el tamaño inicial) se requieren algunos años de uso o un volúmen alto que bien hablaría de la dimensión de un negocio.
¿Qué significa ABC?
Significa “Controlador de Backend Articulable” (ABC, Articulable Backend Controler), también aplica a una función o aplicación cliente (Articulable Backend Client). Es una especificacion para peticiones web que se deriva del lenguaje de programación ABCode, del mismo autor de OnMind (César Andrés Arcila), es decir, es una propuesta de estándar para hacer peticiones a una API de microservicios. El endpoint principal suele ser: localhost:9990/abc
¿Qué es ANY y para qué se usa?
Aunque algunos ejemplos podrían sugerir un concepto abierto, la implementación específica de OnMind utiliza un repositorio con una estructura preestablecida conocida como ANY que se puede pensar con la analogía de una hoja de datos (o big-table). Lo que esto significa es que existe una gran colección y lo que en realidad se hace es mapear los campos o propiedades disponibles. Veamos estos campos de modo general:
| Campo | Descripción |
|---|---|
id |
Reservado como identificador interno y llave principal |
any01 |
Reservado para llave candidata (compuesta internamente usando any02) |
any02 |
Código que compone la llave candidata (requerida). Su llave (o id) |
any03 |
Nombre o título (generalmente corto) |
any04 |
Descripción asociada a los datos o al registro |
any10 |
Dato de texto con longitud superior a los demás |
any11 |
Dato libre inicial (01) |
| … | … |
any60 |
Dato libre final (50) |
Los datos libres comprenden una serie de campos entre
any11yany60(50 posiciones). Normalmente se mapean estos campos considerando la aplicación apropiada de los campos anteriores aany11. Se reservan algunos campos para compatibilidad interna (e.j.any05 ... any09).
Si se está cuestionando si el repositorio de OnMind concentra o sobrecarga la estructura ANY esto depende de cómo se vea. El Método OnMind es el que inspira el repositorio, dónde ANY sólo corresponde a lo que se describe como algo Extra (dinámico, para cualquier cosa), por lo que la implementación completa en realidad sería más focalizada y mejor distribuida. Aunque sí puede concentrarse la información en ciertos casos que bien han sido observados durante más de 5 años con el uso de lo que podemos llamar Big-tables. Esto también requiere un cambio de mentalidad, apertura y no es ideal para quién genere temor o no vea el potencial de Big-data en este sentido.
Evidentemente, al pensar en un mapeo se requiere un modelo lógico o abstracto en la aplicación (cliente o frontend) y esto puede traducirse en seguridad de la información al desconocerse el modelo exacto sin una aplicación cliente o mecanismo que lo especifica.
¿Cómo usar OnMind-XDB? (Aprendizaje Técnico)
Las peticiones a la API tienen un estándar que recibe y gestiona el “Controlador de Backend Articulable” (ABC, Articulable Backend Controler). El endpoint principal suele ser: localhost:9990/abc. Mientras en Javascript puedes usar fetch directamente, nuestro cliente o controlador presenta una especificación de alto nivel como la siguiente:
{
"what": "find",
"some": "persons",
"with": "any03 = 'peter'"
}
Resumiendo, tendríamos los atributos posibles en la siguiente tabla:
| Sentencia | Descripción |
|---|---|
what |
Acciones find, insert, update, delete, create, drop. Además, puede ser invoke, en cuyo caso se usa name en lugar de some |
some |
Colección o hoja de datos (tabla) |
with |
Criterio de consulta o filtro. También puede acompañar name indicando una dirección externa (gateway) |
how |
Campos o métodos aplicables (tales como order, limit, etc.) |
show |
Datos a mostrar |
puts |
Datos a colocar |
cast |
Usado en caso de requerir reportar tipos de datos asociados separados por comas (,) |
name |
Permite invocar método o “plugin” de la API usando puts (y with). Está pensado como un router de funciones y evita rutas en la url |
user |
Usuario que se utiliza. La aplicación cliente lo puede reportar |
role |
Rol con el que se estaría ejecutando la petición |
pass |
Palabra de paso de aplicación |
auth |
Token de autenticación de sesión. Aplica desde código frontend (para petición a la API-Rest) |
Otros productos o versiones de OnMind implementan
fromypin.fromse refiere a arquetipos aplicables sólo para repositorio de plataforma OnMind.pines la “Nomenclatura de Identificación Privada” para gestionar identidad corporativa.
Si surge la pregunta sobre si se logra resolver consultas como en SQL (Structured Query Language) la respuesta simple es no. Tratándose de una base de datos NoSQL no se pueden resolver las consultas del mismo modo. Sin embargo, existen tecnologías alternas como GraphQL que está orientada para una API. Por supuesto, esto sugiere que se debe implementar algo en el lado del cliente cuando la API no cubre ciertas consultas específicas, pero ese es el modo que viene siendo tendencia y en el que se puede introducir GraphQL, aunque en menor grado que con otra API puesto que sí se resuelven muchas consultas directamente con nuestra tecnología como veremos a continuación. Seguramente a futuro la API se puede ampliar para no depender de GraphQL en esos casos específicos.
Se usan los atributos what, some, with, puts, show o how para establecer un patrón en la consulta. Se usa some para la colección o tabla, what para la acción (find, insert, update, delete, create, drop), with para el criterio de búsqueda o filtro, y how para indicaciones complementarias (por ejemplo: order, limit). show cuando encuentras algo and puts podría incluirse para operaciones de insercción o actualización. Veamos el concepto con ejemplos.
create
{
"what": "create",
"some": "persons"
}
createes la primera sentencia a utilizar antes de insertar algo que no se ha definido. En este caso, se puede usarshowpara reportar un título o nombre para el humano, ywithpodría usarse para indicar el módulo interno en el caso de la plataforma OnMind (por defecto se asignaSHEET).useres requerido pero la aplicación cliente lo puede reportar.
find
{
"what": "find",
"some": "persons",
"with": "any03 = 'peter'",
"show": "any03 name, any11 age"
}
Para
findse usashowseparando con,, ywithusa filtro enSQL.
insert
Suponiendo que any03 es el nombre y any11 es la edad, tendríamos:
{
"what": "insert",
"some": "persons",
"puts": {"any03":"peter","any11":25}
}
En este ejemplo de
insertse usaputscon{}(JSON)…
Si se desea usar una herramienta externa como Postman, debe agregarse un Pre-request Script (ubicado al lado del Body), el cual consiste en un código javascript de tan solo 3 líneas para expresar puts en una cadena (escapando el dato), así:
let raw = JSON.parse(pm.request.body.raw);
raw.puts = JSON.stringify(raw.puts);
pm.request.body.raw = JSON.stringify(raw);
update
Suponiendo que conocemos el id y any11 es la edad, tendríamos:
{
"what": "update",
"some": "persons",
"with": "1234567890'",
"puts": {"any11":20}
}
En este caso,
putsestableceage = 20, ywithse refiere alid.
Se aplica el uso deputsescapado cuando se consumo el servicio de modo externo, por ejemplo, desde Postman (o usando un Pre-request Script para evitar el escape).
delete
Semejante a la anterior sentencia, tendríamos:
{
"what": "delete",
"some": "persons",
"with": "1234567890"
}
invoke (name)
Por otra parte, el modo de usar name para extender invocaciones a microservicios en la plataforma (generalmente externos o complementarios) no aplica para OnMind-XDB (salvo login). Es una característica que se está desarrollando para usar con lenguaje de programación ABCode. El ejemplo sería el siguiente:
{
"what": "invoke",
"name": "statistics",
"with": "localhost:3333/abc",
"puts": {"year":2021}
}
withsólo se usa cuando se trata de un microservicio externo (como gateway) o un script (ej.py,js,ts,lua,go). La seguridad es otro asunto que se puede cubrir de diversos modos.
OnMind-XDB & Mule ESB
Una de los casos de uso de OnMind-XDB (o distribuciones superiores) es la integración. Existe software como Mule ESB que puede acceder a peticiones web y utilizar así OnMind-XDB como persistencia de datos.
Debe considerarse que se realizan peticiones con el verbo post y el body se envía en json, por esto se usa un lenguaje como DataWeave para transformar el contenido (tanto del body como en la respuesta). Por ejemplo, podríamos reportar nuestro body así:
%dw 2.0
output application/json
---
{
"what": "find",
"some": "example"
}
Nótese que la sintaxis de arriba es cercana a
Javascript(con una cabecera antes de---).
Como alternativa a DataWeave, Mule permite usar lenguajes de Scripting (ej.Python,Lua,Groovy) o el mismoJava.
En el archivo xml de un proyecto con Mule, un flujo de ejemplo para ilustrar el uso de OnMind-XDB tendría un contenido como el siguiente:
<http:listener-config name="myapi-Listener-Config">
<http:listener-connection host="0.0.0.0" port="8081" />
</http:listener-config>
<http:request-config name="OnMind-XDB" doc:name="HTTP Request config">
<http:request-connection host="localhost" port="9990"/>
</http:request-config>
<flow name="myFlow">
<http:listener doc:name="Listener"
config-ref="myapi-Listener-Config" path="/api"/>
<http:request method="POST" doc:name="Request"
config-ref="OnMind-XDB" path="/abc">
<http:body ><![CDATA[#[%dw 2.0
output application/json
---
{
"what": "find",
"some": "example"
}]]]></http:body>
</http:request>
<set-payload value="#[payload]" doc:name="Set Payload" mimeType="application/json" />
</flow>
Si agregamos un transformador de mensaje de Mule, es posible definir el tipo de la respuesta usando DataWeave, por ejemplo:
%dw 2.0
output application/json
---
payload map ( item , indexOfItem ) -> {
id: item.id,
code: item.any02,
name: item.any03
}
Para comprender el concepto de este caso de uso es mejor ver el video que se ha preparado.
© 2021 by César Andrés Arcila