OnMind-DCE (Database Community Edition)
This is a document that presents OnMind-DCE (OnMind’s community edition database) to accompany projects and as a knowledge base or technical reference of a product whose license is catalogued as freeware and allows its installation under such concept. OnMind-DCE has no licensing cost, nor any warranty, but it is possible to move to an enterprise scheme with the OnMind platform and its product OnMind-EPI, or alternatively OnMind-DAI.
The first thing you must do to use this program is to download the portable software, read the README.md file and execute the respective onmind-dce... file. Then you can create your first object, for example, by copying the following into the program:
{
"what": "create",
"some": "example"
}
CTRL + Ris used to execute the sentence
Essential usage example
If you have advanced technical knowledge, we will make a slight parenthesis before the conceptual introduction, which of course we invite you to review to understand the context. OnMind-DCE is a NoSQL database that implements an API (Application Programming Interface) with JSON (Javascript Object Notation) for querying and managing information, which has been called “Articulable Backend Controller”, or “Articulable Backend Client” when it is an application (client), and is a proposal of the author of OnMind as a specification or technological standard that can be illustrated with the example below:
{
"what": "find",
"some": "example",
"show": "id,any02,any03"
}
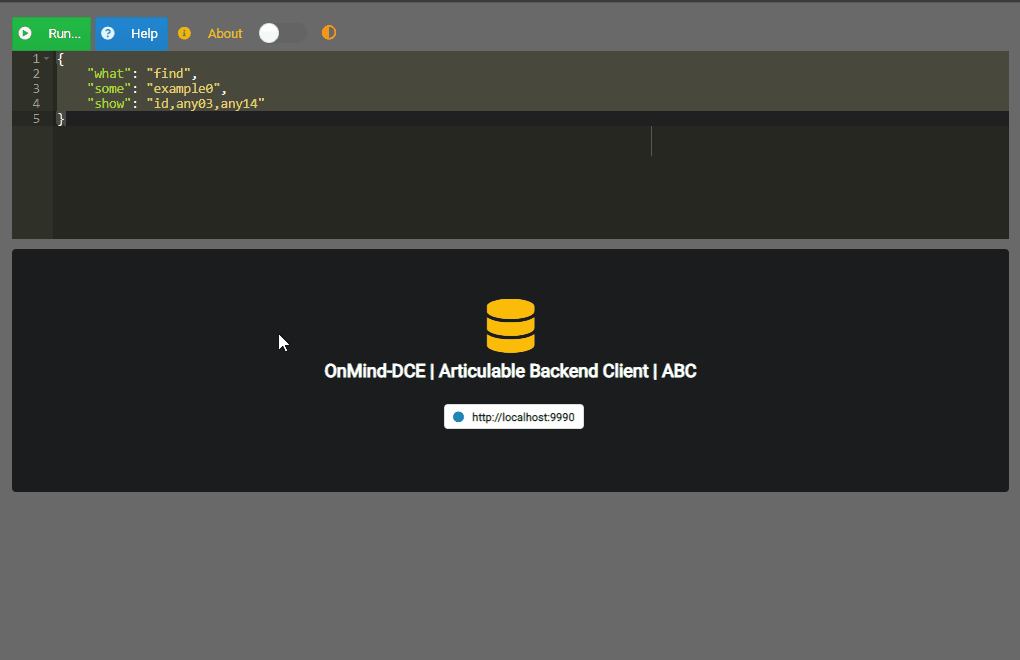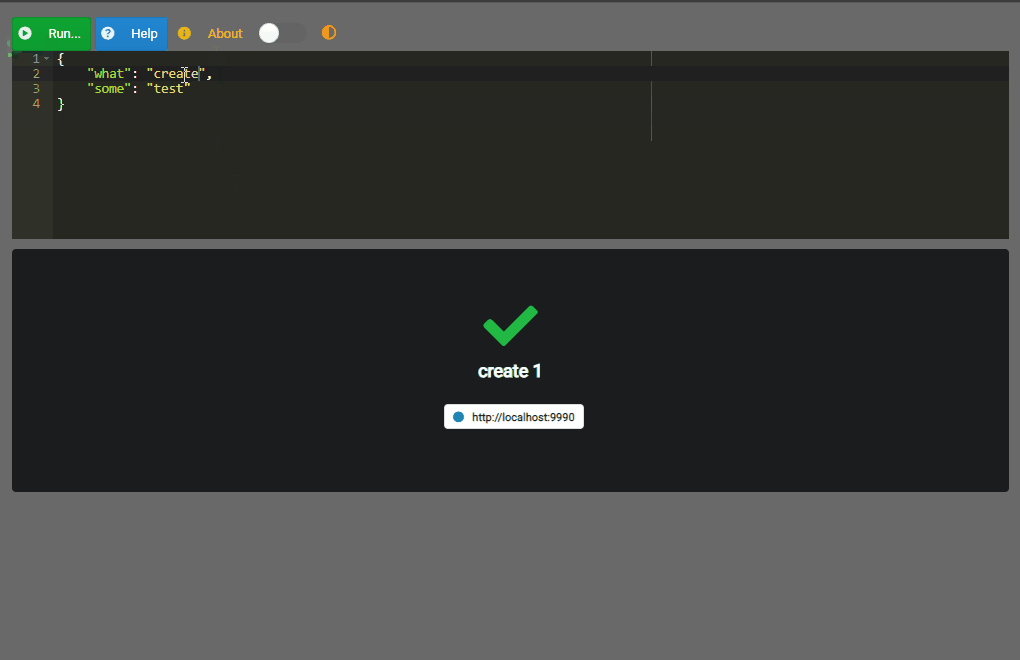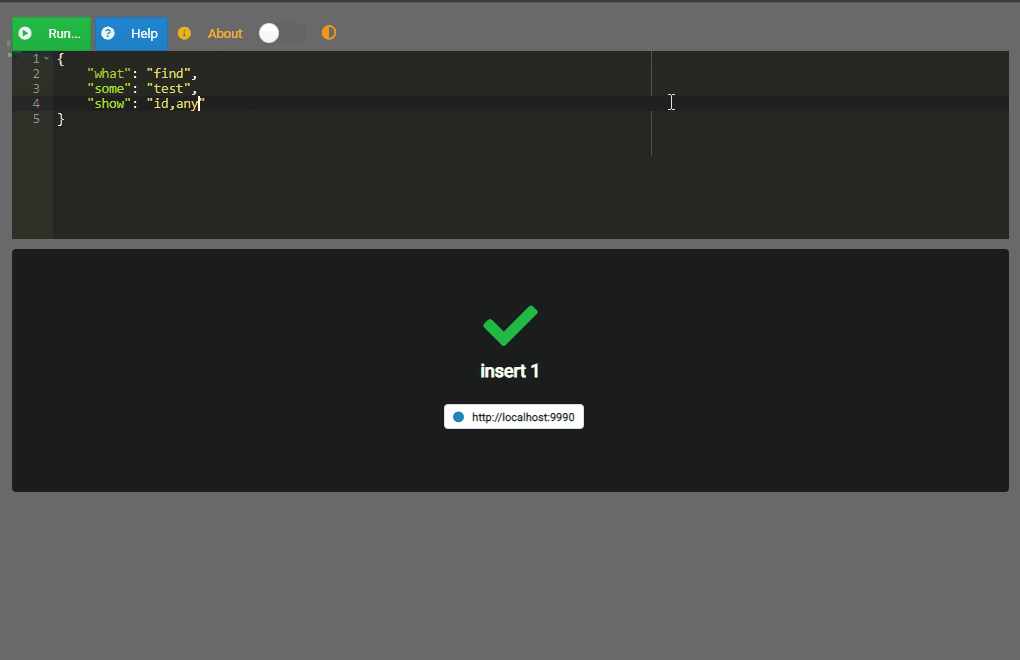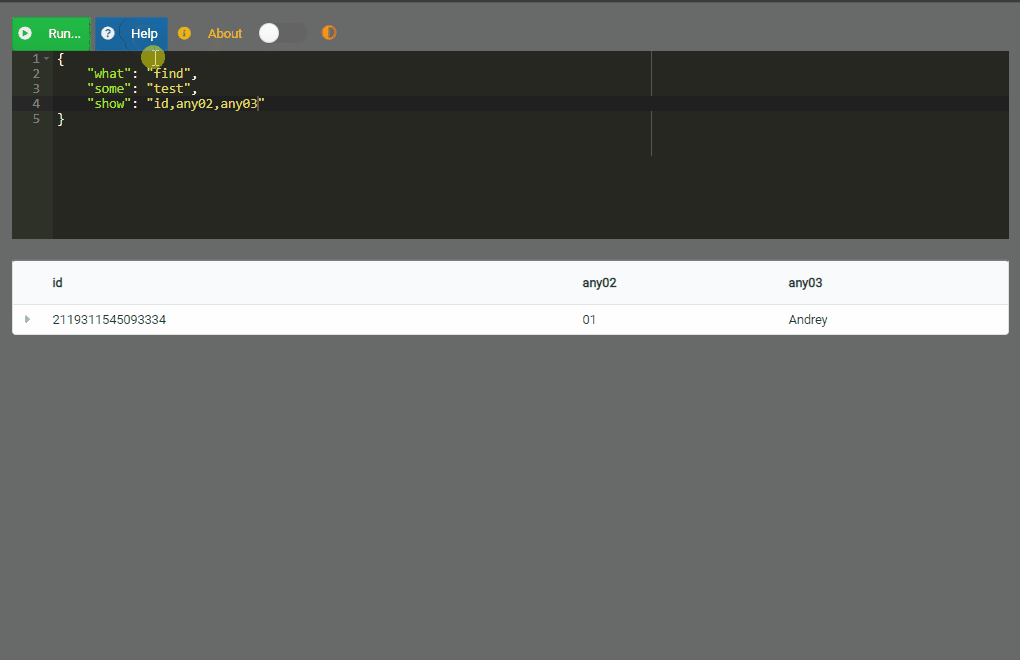
It can be observed that
what,someandshoware indicated to represent respectively “what action”, “about what thing” and “what to show”. In this essential example the action isfind, the thing isexampleand then the data to show is listed separated with commas (,).
Of course you can apply a criterion or condition to filter information (for which you would use the with element) but this can be found further in this documentation. Since data is displayed only if it is found or exists, let’s see an essential example on how to add the information, considering that certain predefined attributes will be used: any02 (id), any03, etc.
{
"what": "insert",
"some": "example",
"puts": {"any02":"01","any03":"Andrey"}
}
Here we can say that the action is
insert, the thing isexamplebut then appears theputselement where the data is reported inJSON(if the service is to be consumed, data are sent separated by semicolons;as will be seen later).
Of course, before inserting information, the thing must have been defined (some), let’s see how…
{
"what": "create",
"some": "example"
}
The main
endpointis usually:localhost:9990/abc. The most appropriate is to follow the steps in reverse order.
In this essential example, certain principles that illustrate an idea have been exposed. For now we invite you to review the concepts and context of this technological proposal.
About the Author
César Andrés Arcila…
OnMind-DCE use cases
OnMind-DCE can be very useful in personal or academic projects, and for small business applications. However, its potential can be used in integration projects (see video at the end).
Another key facet is to focus on Mockup, for agile prototyping of the user interface. As well as to support digital marketing functionalities.
Perhaps a specific version for IoT (Internet of Things) can also become adapted.
What is a Database?
Is a mechanism and computer program in which duly organized data are stored. It may give us a vague notion if we imagine classical libraries or physical archives applying this to the world of information technology. Generally, business applications make use of a database manager (or engine) that belongs to a different manufacturer and can generate an additional cost, although there are decent alternatives to databases without generating licensing costs (different when it involves the support). In many cases, to access the information these data engines use a structured query language (known as SQL), alternatively, those managers that do not use it fall into a group called NoSQL.
What is a Database for?
Databases enable fast and organized access to data and power software applications that are typically in the business or analytical fields, as well as various domains. While some database principles can be applied through spreadsheets in an artisanal way, this would not be comparable to a database engine as such. In fact, this type of technology is also known as a database management system (DBMS) and is applicable to businesses of any size and is the basis for obtaining business information, which is key.
What is OnMind-DCE?
It is the OnMind community edition database manager that can be installed locally. OnMind-DCE is based on an internal version of the platform called OnMind-EPI, as well as OnMind-DAI, and is released in a decoupled mode (external or independent of the OnMind platform) and without the graphical user interface. It is classified as NoSQL since instead of SQL it implements an API (Application Programming Interface). Another major difference of OnMind-DCE with respect to OnMind-EPI is its local approach and that it does not include a backup mechanism, with the understanding that it is easy to find additional tools to backup local files and cover such activity (e.g. [Cobian Backup]): Cobian Backup).
OnMind-DCE is not an ideal product for the cloud or to handle a file that exceeds 1GB, for that you find another product from OnMind. The proposal of this database manager implies that media files, such as images, videos or documents, are managed by other mechanisms such as a simple folder (or a cloud service like Dropbox). That is, the product is designed for flat data or references to external files (links) and not for storing such files. Therefore, data storage can be 10MB to start with and to reach 1GB (a thousand times the initial size) requires a few years of use or a high volume that would speak well of the size of a business.
First was OnMind-DAI, then OnMind-EPI, so OnMind-DCE
If you understand some of OnMind’s services or products, you can see the support for using OnMind-DCE in your projects, whether they are formal, pilot, academic or domestic.
About OnMind-EPI and OnMind-DAI
OnMind’s database management system

OnMind incorporates or couples one mechanism that manages the data with a scope, this may vary within our platform and cloud service plans. OnMind-EPI is the name given to our database management system, meaning Embedded Processing Implementation, which refers to (1) our top level manager implementation, (2) our API or JSON layer, (3) our abstract data model, (4) our repository with metadata, (5) Java database internally embedded and (6) backup function. Although OnMind-EPI may involve inside an SQL (Structured Query Language) layer its connection is made through API, being classified as NoSQL database. It is design to companion OnMind without graphical user interface and make possible certain auto-administration (other than backups). OnMind-EPI is recommended for database file up to a size of 3GB (usually enough for most plans), approaching that dimension is a sign of reviewing a new plan (such as OnMind Optimus).
In the OnMind Optimus plan it is possible to evaluate a project with a database of specific interest that can be adapted through our Database Adapter Interface called OnMind-DAI (substitute for OnMind-EPI without database). OnMind does not provide the database engine in this last scenario and must be acquired or provisioned, it would only incorporate as a mechanism OnMind-DAI that enables the connectivity of manufacturers databases, currently version designed mainly for MySQL/MariaDB (even Amazon Aurora on AWS), as well as Oracle 18c (even XE or 12c, not lesser). It is thus concluded that, if the requirements exceed the scope of OnMind-EPI should be used OnMind-DAI connecting a third party database adopted or viable to adapt under project. Perhaps our technology can be seen as a layer above the database (supra-database) or multi-engine (such as MySQL or MariaDB), or simply consider OnMind-DAI as a pseudo-database but it’s a management system.
Makes projects database independent
Its added value consists of enabling independence from the database engine (at least not to depend on just one), as well as applying an abstract data model oriented under the OnMind Method that promotes agile projects.

Main difference between OnMind-DCE and OnMind-EPI.
The main difference is that OnMind-EPI is incorporated in some plans of the OnMind platform, is currently not distributed separately, and is thought for Linux system (Debian mainly) or Docker containers that require technical knowledge and at least one server (even VPS) or a service like AWS-ECS/Fargate. While OnMind-DCE is mainly thought for desktop systems such as Windows, it is self-administered and its main purpose is for teaching or domestic (solo) office activity, it is not recommended in production environments. OnMind-EPI can triple the capabilities of OnMind-DCE and working in a network or over the Internet is another of its features. Moreover, the new API (experimental) is enabled for OnMind-DCE by default.
One technical difference is that OnMind-DCE uses Servlets technology (currently with Javalin & Jetty) which has been a common component in the Java world, while other OnMind products use Vert.x which forces an always asynchronous programming.
You can have access to OnMind-EPI by applying to some of the concepts or applications in the OnMind store according to the plans for projects (Plus, Virtus, Optimus), which would enable the
API. You can also apply to OnMind-DAI according to the concept and service (extra). For a demonstration in enterprise infrastructure do not hesitate to contact us.
What does ABC mean?
It means “Articulable Backend Controller” (ABC), it also applies to a function or client application (Articulable Backend Client). It is a specification for web requests that is derived from the programming language ABCode, by the same author of OnMind (César Andrés Arcila), i.e., it is a proposed standard for making requests to a microservice API. The main endpoint is usually localhost:9990/abc.
What is ANY and what is it used for?
Although some examples might suggest an open concept, the specific implementation of OnMind uses a repository with a pre-established structure known as ANY which can be thought of with the analogy of a datasheet (or big-table). What this means is that there is a large collection and what is actually done is to map the available fields or properties. Let’s look at these fields in a general way:
| Field | Description |
|---|---|
id |
Reserved as internal identifier and primary key |
any01 |
Reserved for candidate key (internally composed, using any02) |
any02 |
Code that composes the candidate key (required). Your key (or id) |
any03 |
Name or title (usually short) |
any04 |
Description associated with the data or the record |
any10 |
Text data longer than the others |
any11 |
Initial free data (01) |
| … | … |
any60 |
Final free data (50) |
The free data comprises a series of fields between
any11andany60(50 positions). Normally these fields are mapped considering the appropriate application of the fields aboveany11. Some fields are reserved for internal compatibility (e.g.any05 ... any09).
If you are questioning whether the OnMind repository concentrates or overloads the ANY structure, this depends on how you look at it. The OnMind Method is what inspires the repository, where ANY only corresponds to what is described as something Extra (dynamic, for anything), so the full implementation would actually be more targeted and better distributed. Although the information can be concentrated in certain cases that have been observed for more than 5 years with the use of what we can call Big-tables. This also requires a change of mentality, openness and is not suitable for those who generate fear or do not see the potential of Big-data.
Evidently, when thinking about a mapping, a logical or abstract model is required in the application (client or frontend) and this may result in information security as the exact model is unknown without a client application or mechanism specifying it.
How to use OnMind-DCE? (Technical Learning)
Requests to the API have a standard that is received and managed by the “Articulable Backend Controller” (ABC). The main endpoint is usually: localhost:9990/abc. While in Javascript you can use fetch directly, our client or controller presents a high-level specification like the following:
{
"what": "find",
"some": "persons",
"with": "any03 = 'peter'"
}
Summarizing, we would have the possible attributes in the following table:
| Sentence | Description |
|---|---|
what |
Actions find, insert, update, delete, create, drop. In addition, it can be invoke, in which case name is used instead of some |
some |
Collection or datasheet (table) |
with |
Query criteria or filter. It can also accompany name indicating an external address (gateway) |
how |
Applicable fields or methods (such as order, limit, etc.) |
show |
Data to show |
puts |
Data to place |
cast |
Used in case of needing to report associated data types separated by commas (,) |
name |
Allows to invoke method or plugin of the API using puts (and with). It is thought as a function router and avoids routes in the url |
user |
User to be used. Can be reported by the client application |
role |
Role under which the request would be executed |
pass |
Application pass word |
auth |
Session authentication token. Applies from frontend code (for API-Rest request). |
Other OnMind products or versions implement
fromandpin.fromrefers to archetypes applicable only for OnMind platform repository.pinis the “Private Identity Nomenclature” for managing corporate identity.
If the question arises as to whether it is possible to solve queries as in SQL (Structured Query Language) the simple answer is no. Being a NoSQL database it is not possible to solve queries in the same way. However, there are alternative technologies such as GraphQL which is oriented for API. Of course, this suggests that something must be implemented on the client side when the API does not cover certain specific queries, but that is the mode that has been trending and where GraphQL can be introduced, although to a lesser degree than with other API since many queries are resolved directly with our technology as we will see below. Surely in the future the API can be extended to not depend on GraphQL in those specific cases.
The what, some, with, puts, show or how attributes are used to set a pattern in the query. You use some for the collection or table, what for the action (find, insert, update, delete, create, drop), with for the search criteria or filter, and how for supplementary indications (e.g. order, limit). show when you find something and puts could be included for insert or update operations. Let’s see the concept with examples.
create
{
"what": "create",
"some": "persons"
}
createis the first statement to use before inserting something that has not been defined. In this case,showcan be used to report a title or name for the human, andwithcould be used to indicate the internal module in the case of the OnMind platform (by defaultSHEETis assigned).useris required but can be reported by the client application
find
{
"what": "find",
"some": "persons",
"with": "any03 = 'peter'",
"show": "any03 name, any11 age"
}
For
finduseshowseparated with,, andwithuse filter inSQL.
insert
Assuming any03 is the name and any11 is the age, we would have:
{
"what": "insert",
"some": "persons",
"puts": {"any03":"peter","any11":25}
}
In this example of
insertwe useputswith{}(JSON)…
If you want to use an external tool like Postman, you must add a Pre-request Script (located next to the Body), which consists of a javascript code of only 3 lines to express puts in a string (escaping the data), like this:
let raw = JSON.parse(pm.request.body.raw);
raw.puts = JSON.stringify(raw.puts);
pm.request.body.raw = JSON.stringify(raw);
update
Assuming we know the id and any11 is the age, we would have:
{
"what": "update",
"some": "persons",
"with": "1234567890",
"puts": {"any11":20}
}
In this case,
putssetsage = 20, andwithrefers to theid.
The use of escapedputsis applied when consuming the external mode service, e.g. from Postman (or using a Pre-request Script to avoid the escape).
delete
Similar to the previous sentence, we would have:
{
"what": "delete",
"some": "persons",
"with": "1234567890"
}
invoke (name)
On the other hand, the way to use name to extend invocations to microservices on the platform (generally external or complementary) does not apply to OnMind-DCE (except login). It is a feature being developed for use with programming language ABCode. The example would be as follows:
{
"what": "invoke",
"name": "statistics",
"with": "localhost:3333/abc",
"puts": {"year":2021}
}
withis only used when dealing with an external microservice (as a gateway) or a script (e.g.py,js,ts,lua,go). Security is another matter that can be covered in a variety of ways.
OnMind-DCE & Mule ESB
One of the use cases of OnMind-DCE (or higher distributions) is integration. There is software such as Mule ESB that can access web requests and thus use OnMind-DCE as data persistence.
It should be considered that requests are made with the post verb and the body is sent in json, this is why a language like DataWeave is used to transform the content (both in the body and in the response). For example, we could report our body like this:
%dw 2.0
output application/json
---
{
"what": "find",
"some": "example"
}
Note that the syntax above is close to
Javascript(with a header before---).
As an alternative to DataWeave, Mule allows the use of Scripting languages (e.g.Python,Lua,Groovy) orJavaitself.
In the xml file of a project with Mule, an example flow to illustrate the use of OnMind-DCE would have a content like the following:
<http:listener-config name="myapi-Listener-Config">
<http:listener-connection host="0.0.0.0" port="8081" />
</http:listener-config>
<http:request-config name="OnMind-DCE" doc:name="HTTP Request config">
<http:request-connection host="localhost" port="9990"/>
</http:request-config>
<flow name="myFlow">
<http:listener doc:name="Listener"
config-ref="myapi-Listener-Config" path="/api"/>
<http:request method="POST" doc:name="Request"
config-ref="OnMind-DCE" path="/abc">
<http:body ><![CDATA[#[%dw 2.0
output application/json
---
{
"what": "find",
"some": "example"
}]]]></http:body>
</http:request>
<set-payload value="#[payload]" doc:name="Set Payload" mimeType="application/json" />
</flow>
If we add a Mule message transformer, it is possible to define the type of the response using DataWeave, for example:
%dw 2.0
output application/json
---
payload map ( item , indexOfItem ) -> {
id: item.id,
code: item.any02,
name: item.any03
}
To understand the concept of this use case it is best to watch the video that has been prepared.
© 2021 by César Andrés Arcila